From Data Lakes to Data Lakehouses: Navigating the Future of Big Data Storage
Explore the evolution from traditional data lakes to modern data lakehouses, and learn how this shift is revolutionizing big data storage with enhance

Introduction to Data Lake
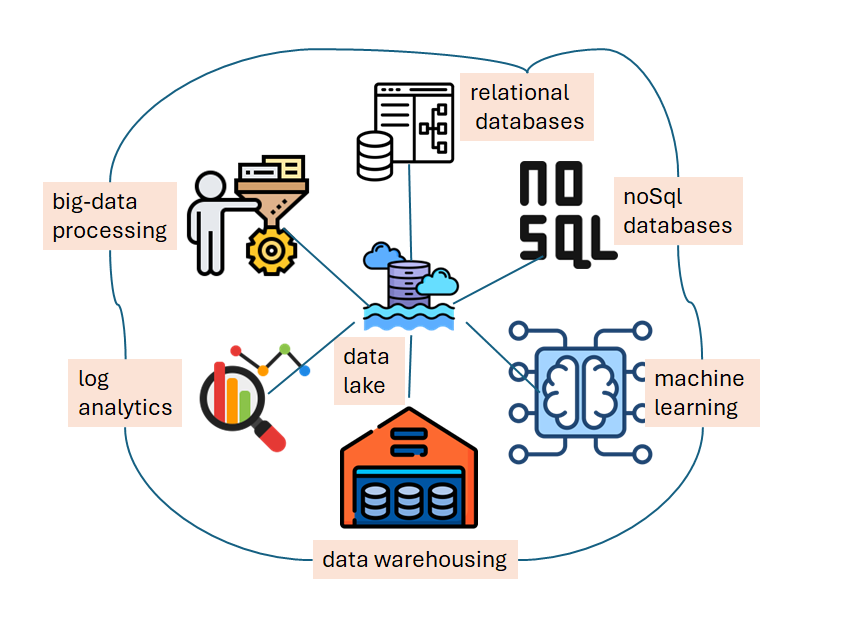
A data lake is a centralized repository that allows you to store all types of data, whether structured, semi-structured, or unstructured, in a raw format. It functions like a large storage system, similar to the C drive on your computer, but with a crucial difference: it offers virtually unlimited scalability. Unlike your computer's disk drives, which are limited in capacity, a data lake can scale up to accommodate vast amounts of data—terabytes or even petabytes—without requiring additional hardware or infrastructure.
Key Principles of a Data Lake
Schema on Read:
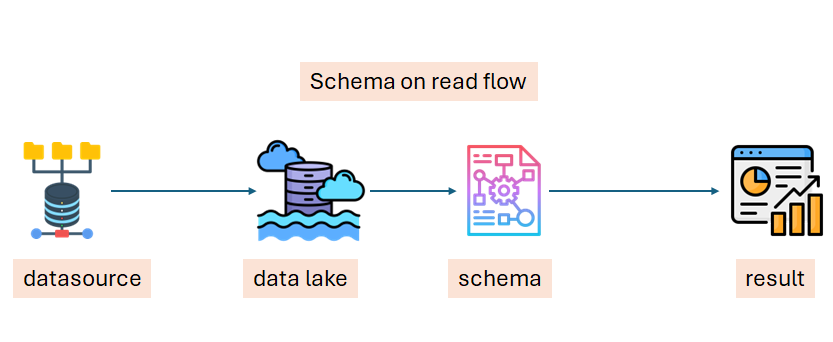
Definition: Data lakes follow the principle of "schema on read," meaning that data is stored in its raw form without enforcing any structure during the write process. The structure and format are only applied when the data is read or queried.
Advantage: This approach lowers the barrier to data entry, making it easier and faster to store data without worrying about its structure upfront. This flexibility encourages the ingestion of diverse data types.
Challenge: Over time, without proper data governance, the data lake can become disorganized, resembling a polluted body of water with a mix of clean and contaminated data.
In-Place Analytics:
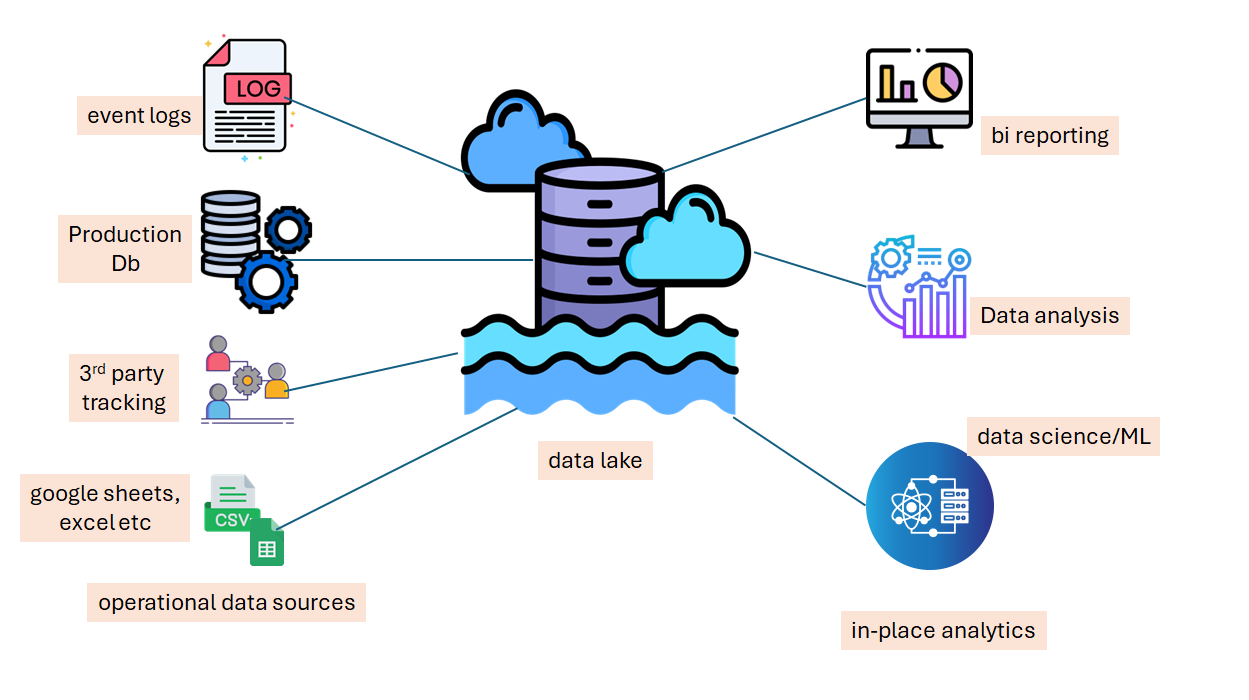
Definition: Thanks to schema on read, data lakes allow different users to analyze the same dataset in various ways without creating multiple copies. For instance, a data scientist might create a view with three columns for a specific analysis, while a data analyst might create a view with five columns for a dashboard.
Advantage: This saves both storage space and processing time, as there's no need to duplicate data for different use cases.
ELT (Extract, Load, Transform):
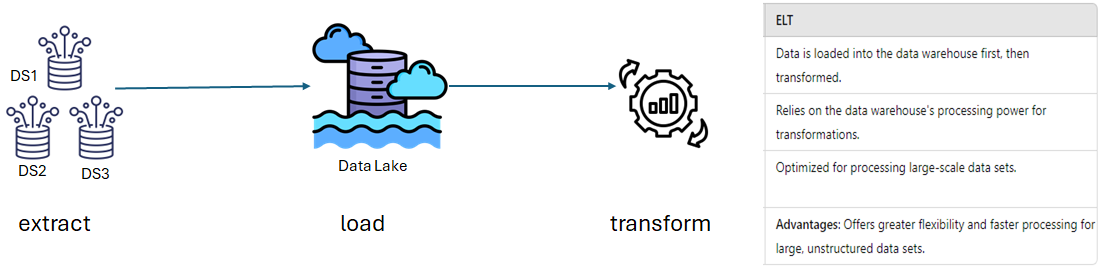
Definition: In the data lake architecture, data is first extracted from the source and loaded into the data lake in its raw form. The transformation occurs later, based on specific use cases.
Comparison to ETL: In traditional ETL processes used in data warehouses, data is transformed before being loaded. This is because data warehouses enforce a strict schema during the loading process, whereas data lakes apply the schema only when data is read.
Technology Used to Build Data Lakes
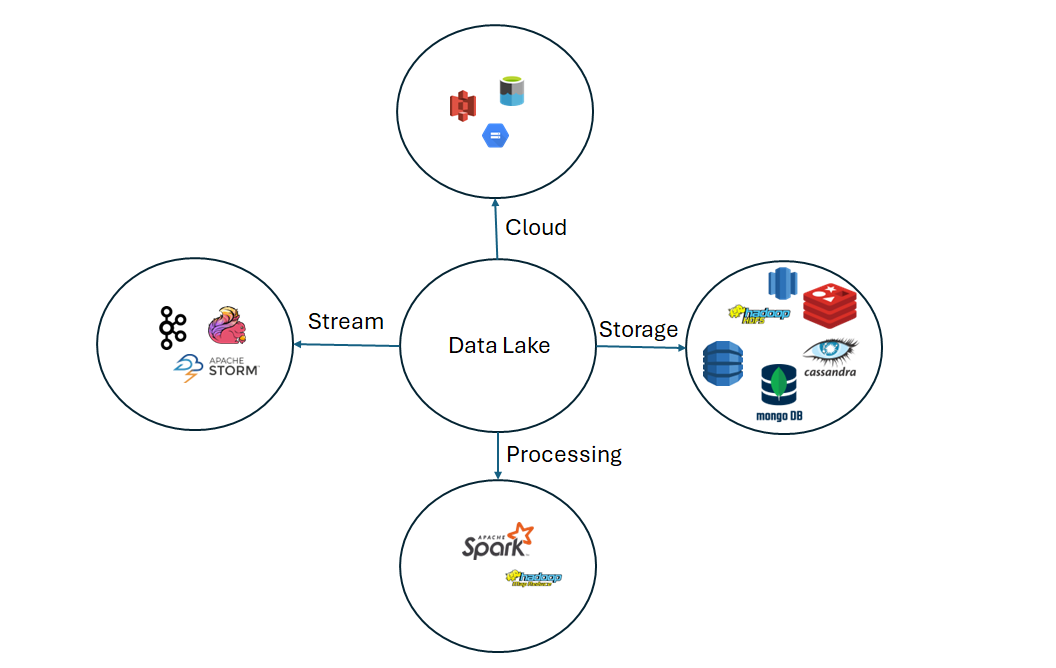
The backbone of most data lakes is cloud storage, which provides the necessary scalability, security, and flexibility. The most popular cloud storage services for building data lakes include:
Amazon S3 (Simple Storage Service): One of the first and most widely used cloud storage services, particularly popular for its robustness and vast ecosystem.
Azure Data Lake Storage (ADLS): Microsoft's offering, designed to handle massive amounts of data and integrate well with other Azure services.
Google Cloud Storage (GCS): Known for its performance and scalability, GCS is favored by industries like oil and gas for its cost-effectiveness.
On-Premises Solutions: For organizations with strict regulatory requirements, on-premises solutions like Hadoop Distributed File System (HDFS) or object storage from vendors like IBM, Hitachi, and NetApp are used. These systems offer similar scalability but within the controlled environment of a private data center.
Challenges with Data Lakes
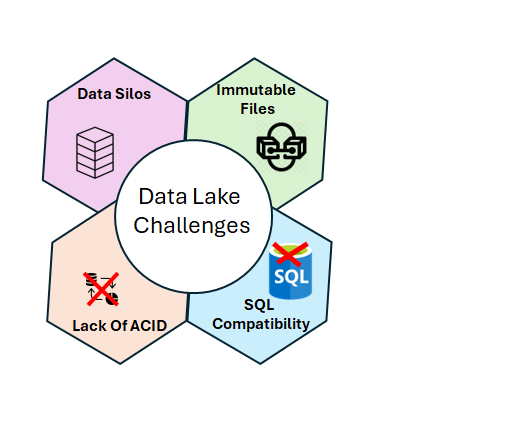
While data lakes offer flexibility and scalability, they come with challenges:
Data Silos: Data lakes can create silos where data scientists and data analysts use different tools and technologies to work on different types of data, limiting collaboration.
Immutable Files: Data in a data lake is often immutable, meaning it cannot be modified in place. This can complicate the processing of streaming data or data that requires frequent updates.
Lack of ACID Guarantees: Data lakes do not natively support ACID (Atomicity, Consistency, Isolation, Durability) transactions, making it difficult to maintain data integrity when multiple processes access the same dataset simultaneously.
SQL Compatibility: Traditional data analysts who rely on SQL may find it challenging to work with data lakes, as they do not inherently support SQL querying.
Introduction to the Data Lakehouse
To address these challenges, the concept of a Data Lakehouse has emerged. A data lakehouse combines the flexibility of data lakes with the reliability and performance of data warehouses. It typically includes three main components:
Delta Lake: An open-source storage layer that adds ACID transaction support to data lakes, ensuring data reliability and consistency.
SQL Query Engine: Allows users to query the data lakehouse using SQL, bridging the gap for data analysts.
Data Catalog: A system to organize and manage the metadata of the stored data, making it easier to discover and work with datasets.
By integrating these components, a data lakehouse enables organizations to store, process, and analyze large amounts of data with the robustness of a data warehouse and the flexibility of a data lake.
Conclusion
As the data landscape continues to evolve, the shift from data lakes to data lakehouses marks a significant step forward in how we manage and derive value from big data. By bridging the gap between data lakes and data warehouses, lakehouses offer a unified, scalable, and high-performance solution for modern data challenges. However, this transformation is just the beginning. As organizations continue to embrace AI, machine learning, and real-time analytics, the future of data architecture promises even more innovations and possibilities. Stay tuned as we explore these emerging trends and the next wave of advancements in data management in our upcoming discussions.
Did you find this helpful?